Mendeteksi Transaksi Kartu Kredit Fraud Menggunakan Neural Network

Machine learning merupakan teknologi dimana sebuah mesin bisa mempelajari sesuatu dari data yang diberikan, sehingga mesin bisa menemukan suatu pola dari data tersebut. Pola inilah yang digunakan mesin untuk memprediksi suatu data.Dalam tutorial kali ini, aku akan mencoba salah satu algoritma supervised learning yaitu Neural Network untuk mengklasifikasi apakah suatu transaksi fraud atau tidak fraud.
Dataset Kartu Kredit
Aku dan beberapa temanku membuat dataset kartu kredit ini dengan beberapa asumsi. Asumsi ini kami dapatkan dari beberapa literatur dan juga wawancara. Asumsi jika transaksi dilabeli fraud adalah :
- Transaksi yang menggunakan verifikasi tanda tangan di atas kertas lebih rentan dilabeli fraud karena bisa saja tanda tangan tersebut palsu atau tidak sesuai dengan aslinya.
- Apabila saat melakukan transaksi terdapat percobaan menekan PIN lebih dari 3 kali, maka dapat dilabeli fraud, karena bisa saja fraudster tidak tahu PIN dari kartu kredit tersebut.
- Jumlah transaksi yang melebihi limit yang merupakan salah satu anomali yang disebut di atas.
- Waktu transaksi yang tidak wajar, transaksi yang dilakukan saat dini hari, bisa saja transaksi dilakukan di tempat yang memiliki zona waktu yang sangat jauh. Contoh bisa saja fraudster melakukan transaksi di AS saat pagi hari, dimana di Indonesia saat malam hari.
- Transaksi yang dilakukan di tempat yang sangat jauh yang merupakan salah satu anomali yang disebut di atas
- Transaksi yang dilakukan oleh e-mail yang tidak sesuai dengan e-mail pemilik.
Pembuatan dataset dengan constraint berikut :
- Amount : Nominal transaksi yang dilakukan.
- Pin_attempt : Percobaan menekan PIN
- Is_signature : 0 = tidak ditandatangani / 1 = ditandatangani
- Cc_limit (limit kartu kredit) : 5000000 / 15000000 / 20000000 / 50000000 / 450000000
- Last_use_accum : Jumlah penggunaan terakhir menggunakan kartu kredit
- Hour : Dari 0 - 23
- Most_place_zipcode : Dilihat dari link ini
- Transaction_place_zipcode : Dilihat dari link ini
- Domain : 1 = gmail.com / 2 = yahoo.com / 3 = hotmail.com / 4 = aol.com / 5 = live.com / 6 = ymail.com / 7 = outlook.com / 8 = yahoo.co.id
- Class : 0 = tidak fraud / 1 = fraud
Dataset berisi total data 368 data dengan 203 data tidak fraud (class 0) dan 165 data fraud (class 1). Kemudian penulis melakukan encode atribut-atribut tersebut menjadi A1-A9 agar lebih mudah dibaca. Berikut nama atribut sebelum perubahan dengan perubahannya :
- Amount menjadi A1
- Pin_attempt menjadi A2
- Is_signature menjadi A3
- Cc_limit menjadi A4
- Last_use_accum menjadi A5
- Hour menjadi A6
- Most_place_zipcode menjadi A7
- Transaction_place_zipcode menjadi A8
- Domain menjadi A9
Langkah-langkah
Langkah-langkah ini dilakukan di Jupyter Notebook :
Mengimpor library yang digunakan untuk klasifikasi.
Mengimpor dataset yang akan diklasifikasi

Mengecek apakah ada data yang kosong pada setiap atributnya

Standarisasi
Melakukan normalisasi pada semua atribut. Atribut dinormalisasi dengan tujuan agar bisa dipelajari oleh model dengan mudah. Dinormalisasi menggunakan rumus standardization yaitu


Pembagian Train Sample dan Test Sample
Membagi dataset menjadi dua bagian yaitu train untuk dipelajari model dan test untuk diprediksi oleh model. Jumlah untuk data test sebesar 30% dari seluruh data. Sehingga 111 data digunakan untuk test.
Pembuatan Neural Network
Pembuatan Neural Network dengan 9 neuron (9 atribut data) dalam input layer kemudian diikuti 2 hidden layer yang masing-masingnya 15 neuron, kemudian diikuti output layer yang masing-masingnya 1 neuron. Masing-masing neuron dalam hidden layer menggunakan ReLU activation function. Sedangkan neuron dalam output layer menggunakan Sigmoid activation function.
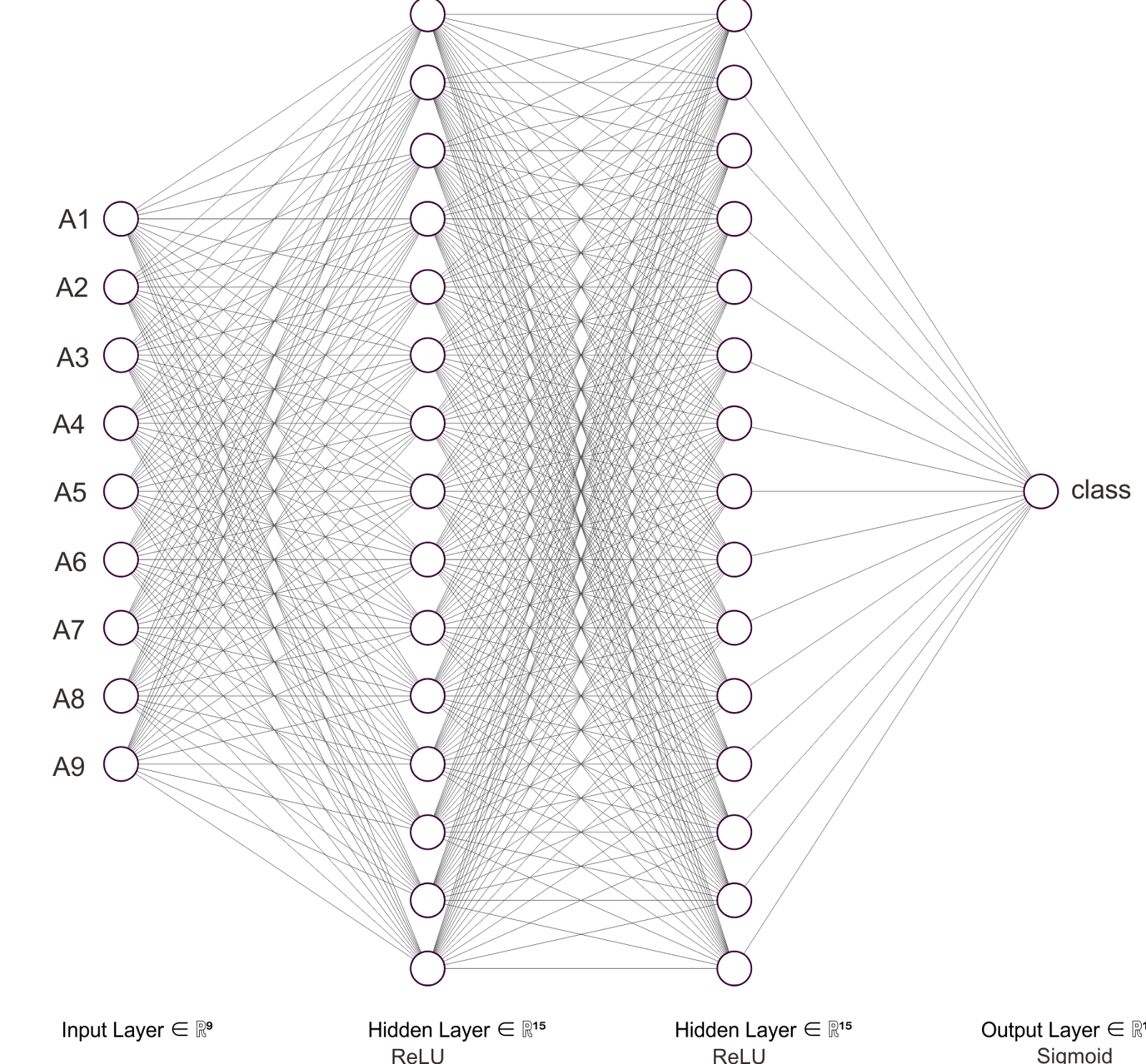
Menampilkan kurva akurasi dan loss
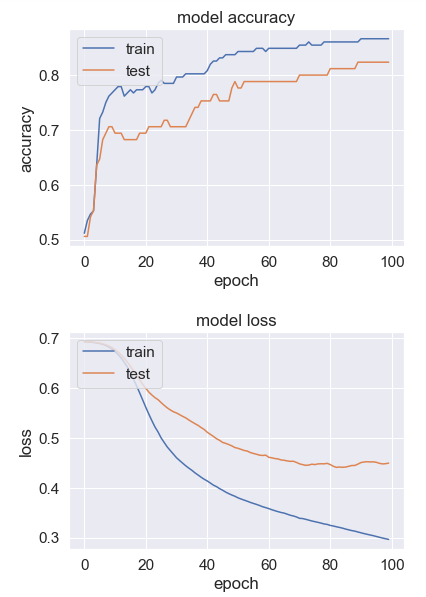
Menampilkan nilai akurasi dan loss

Nilai akurasi test adalah 0,85
Nilai loss train adalah 0,34
Nilai akurasi train adalah 0,85
Menampilkan classification report

Menampilkan Confusion Matrix

Kesimpulan
Hasilnya terbilang cukup bagus dapat dilihat dari akurasinya sebesar 0.87 dan dari confusion matrix, hampir sebagian besar klasifikasi benar. Akan lebih bagus lagi, jika jumlah data diperbanyak. Tutorial ini terinspirasi dari https://blog.usejournal.com/credit-card-fraud-detection-by-neural-network-in-keras-4bd81cc9e7fe

Gan mau nanya kalo untuk proses praprocessing data y gimana ya langkah2 y. Sampe terbentuk dataset yg siap di olah ke data mining. Misal saya dapet data mentah data transaksi penjualan, nah agar bisa di olah kan perlu pra processing data dulu.
BalasHapusSaya masih miss di pra processing data y.
Terima kasih gan
Tergantung sih, ada beberapa metode kayak scaling untuk numerik, label encoding kalau kategorikal. Bisa dilihat di https://hackernoon.com/what-steps-should-one-take-while-doing-data-preprocessing-502c993e1caa untuk lengkapnya
Hapus